Scaling Out Sui Execution with Pilotfish
New research paves the way for the Sui blockchain to enable Validators to scale in support of vastly increased execution performance.

Pilotfish, the first multi-machine smart contract execution engine, enables Sui network validators to use multiple machines and autoscale to execute more transactions when the load increases. This is achieved without compromising reliability or feature completeness.
Pilotfish recovers from failures of internal execution machines and supports the Sui's full dynamic operations. Its streaming architecture leads to a very low latency overhead. Our performance evaluations of the Pilotfish integration with Sui demonstrate an up to eight times throughput increase when using eight servers for execution, demonstrating linear scaling for compute-bound loads.
The challenge of execution
Lazy blockchains are a promising emerging design architecture that decouples transaction ordering (consensus) and execution. In this design, an ordering layer sequences transactions, and then, at a later time, an execution layer executes the transaction sequence. This enables state-of-the-art blockchain systems to order a large number of transactions (on the order of 100,000 transactions per second), using modern consensus algorithms such as Bullshark and Hammerhead. However, execution performance has been lagging behind, and nowadays execution is the bottleneck. For example, the Ethereum virtual machine is reported to peak at only 20,000 transactions per second when executing simple transactions.
Batching: A high-latency solution
One solution to the execution bottleneck is batching. By constructing batches or blocks of a large number of transactions and submitting them as a unit to be executed, it is possible to achieve high throughput without major changes to the architecture. However, batching comes at the cost of high latency. It is not uncommon for batched execution to have latency in the hundreds of milliseconds, which is non-negligible for low-latency blockchains such as Sui.
Pilotfish achieves high throughput while only introducing a negligible latency overhead, in the range of tens of milliseconds rather than hundreds, following the established stream-processing approach already employed in Sui for multi-core execution.
Scaling up versus scaling out
One way to achieve high throughput while keeping latency low is scaling up. Parallel transaction execution on a single machine, and some blockchains, including Sui, successfully employ this model. It has the advantage of not requiring huge architectural changes. The validator is already entirely located on a single machine, making it just a question of executing the transaction in parallel instead of sequentially while preserving transaction causality.
With the scale up approach, once the current load is beyond what your current machine can handle, your only choice is to upgrade to a more powerful machine. But this solution has a limited runway. There are only so many CPU cores that can fit in a server, so much RAM, etc. So if the load keeps growing, eventually it will be beyond the means of any single machine to keep up. Adding insult to injury, it is not only the CPU that might be exhausted but any single resource of the machine. Even if the current validator machine is not saturated CPU-wise for the current load, it might run out of RAM capacity and be forced to rely on slow persistent storage, thus slowing down the entire pipeline. Finally, relying on single powerful machines is unfriendly to the blockchain space, as beefy machines are rare and supported by only a few data-center providers.
The only other way to solve the execution bottleneck, which Pilotfish pioneers in the blockchain space, is scaling out through distributed transaction execution on multiple machines. The advantage of the scale out approach is that it has the potential to scale indefinitely. When load increases beyond the capacity of the current number of machines, we can just spin up more machines, essentially guaranteeing that we never run out of capacity and never have to resort to slow, persistent storage on the critical path. Another advantage of this approach is that it is orthogonal to, and compatible with, the scale up approach. Finally, it also allows for easier decentralization, preventing hardware provider “monoculture.” There is a larger market for multiple small machines than for single super-powerful machines.
How Pilotfish works
Here is how Pilotfish distributes transaction execution on multiple machines. Each validator is internally split into three logical roles: (1) the Primary, which handles consensus, (2) SequencingWorkers (SWs), which store transactions and dispatch them for execution; and (3) ExecutionWorkers (EWs), which store the blockchain state and execute transactions received from the SWs.
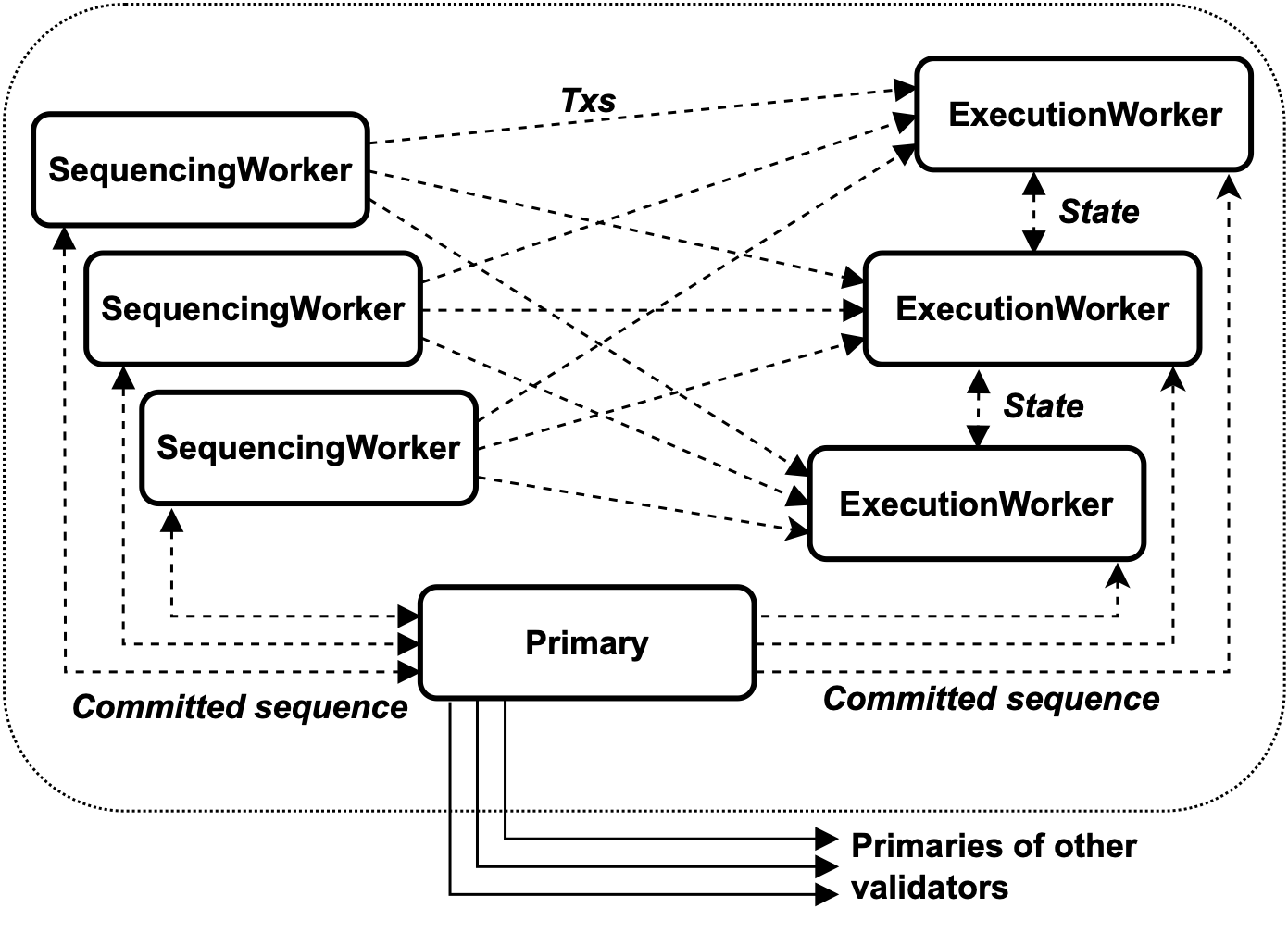
Each of these roles is instantiated on one or more machines, except for the Primary, which is always a single machine. Note that the machines that compose a validator trust each other (they are run by the same entity), so they do not need heavyweight Byzantine Fault Tolerant (BFT) protocols to coordinate. Only the Primary requires BFT, when it interacts with other nodes.
What allows Pilotfish to scale is that SWs and EWs shard the state. Each transaction is assigned to a single SW and each blockchain object is assigned to a single EW. Note that this is not the same as inter-validator sharding, in which validators are assigned different subsets of the state. In Pilotfish, all validators are assigned the entire state, and the sharding happens inside each validator that uses many machines.
In a perfect world, each transaction would only access objects from a single shard, so distributing transaction execution would be as simple as dispatching each transaction to its proper EW shard. However, in the real world, transactions will often access objects from more than one shard. To handle such cross-shard transactions, Pilotfish EWs exchange object data on a per-needed basis, so that the EW designated to execute a given transaction always has the required object data before it starts executing.
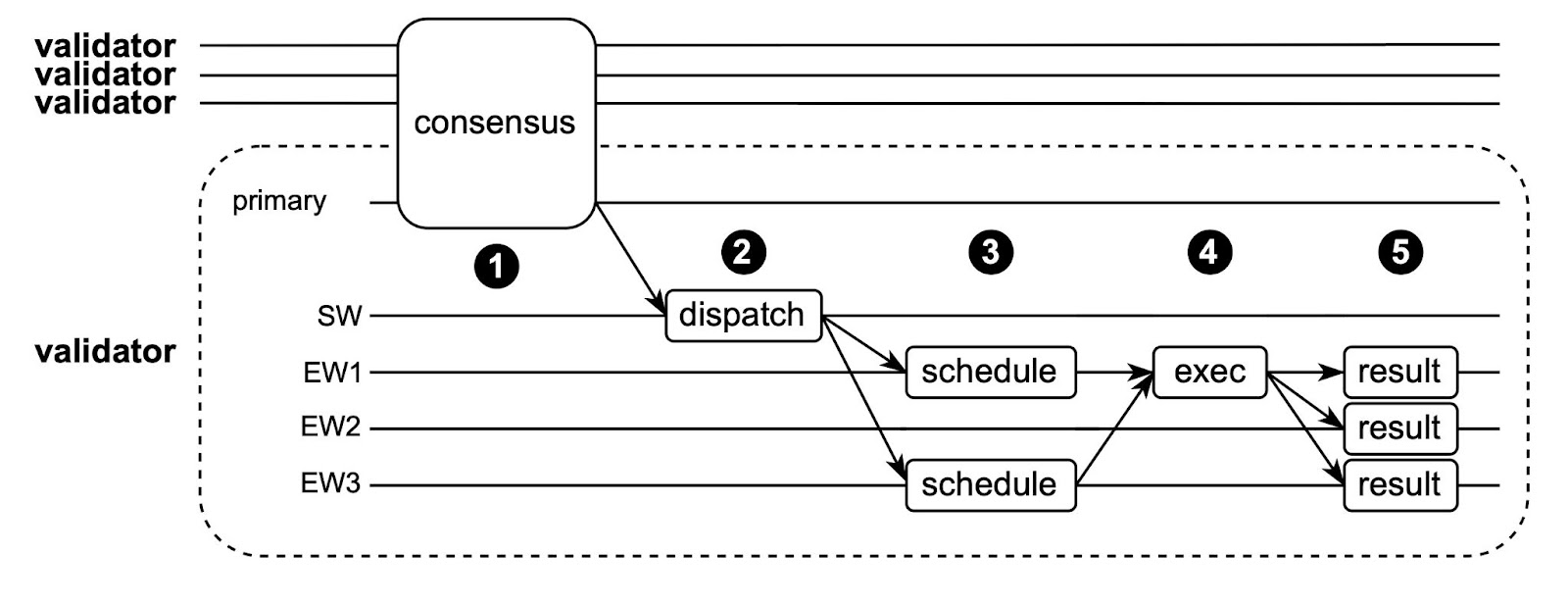
In the diagram above, the Primary interacts with the primaries of other validators to order transactions (➊). The SW receives the transaction ordering information from the primary and dispatches transactions to the appropriate EWs (➋). In our example above, the current transaction T accesses input objects from shards EW1 and EW3, so the SW only dispatches T to those EWs. Then EW1 and EW3 each schedule T against other transactions that may conflict with T (more about our scheduling algorithm in the full paper) (➌). Once T is ready to execute, EW1 and EW3 send the appropriate object data to the designated executor of T (in this case the designated executor is EW1, so only EW3 needs to send objects). Once EW1 has all the required object data, it executes T (➍) and sends the output effects to all EWs. Each EW applies locally changes to objects it owns (➎).
Beyond the basics
Besides this basic transaction flow, read our full paper to find out:
- How we schedule transactions to allow parallel execution of non-conflicting transactions.
- How we handle and recover from shard crashes.
- How we enable reads and writes over dynamic fields.
A quick look at our results
Here we have a quick look at the experimental results. The paper contains full details of the experimental setup and results.
In the latency versus throughput graph below, each data point represents an experimental run in which the SequencingWorker submits transactions at a fixed rate for a duration of five minutes. We experimentally increase the load of transactions sent to the system and record the median throughput and latency of executed transactions. As a result, all plots illustrate the steady state latency of all systems under low load as well as the maximal throughput they can serve, after which latency grows quickly. This is the throughput at which the latency shoots up to over 20 milliseconds.
We emphasize that, in all experiments, transactions are submitted for execution individually, as they arrive in a streaming fashion, without being batched. This is especially important to Sui, which processes fast-path transactions asynchronously as soon as they are certified, before they are batched in a consensus commit. Pilotfish alo supports batching, which significantly increases throughput but (of course) also leads to higher latency.
In this first workload, each transaction is a simple transfer of coins from one address to another. We generate the transactions such that no two transactions conflict. Each transaction operates on a different set of objects from the other transactions. Thus, this workload is completely parallelizable.
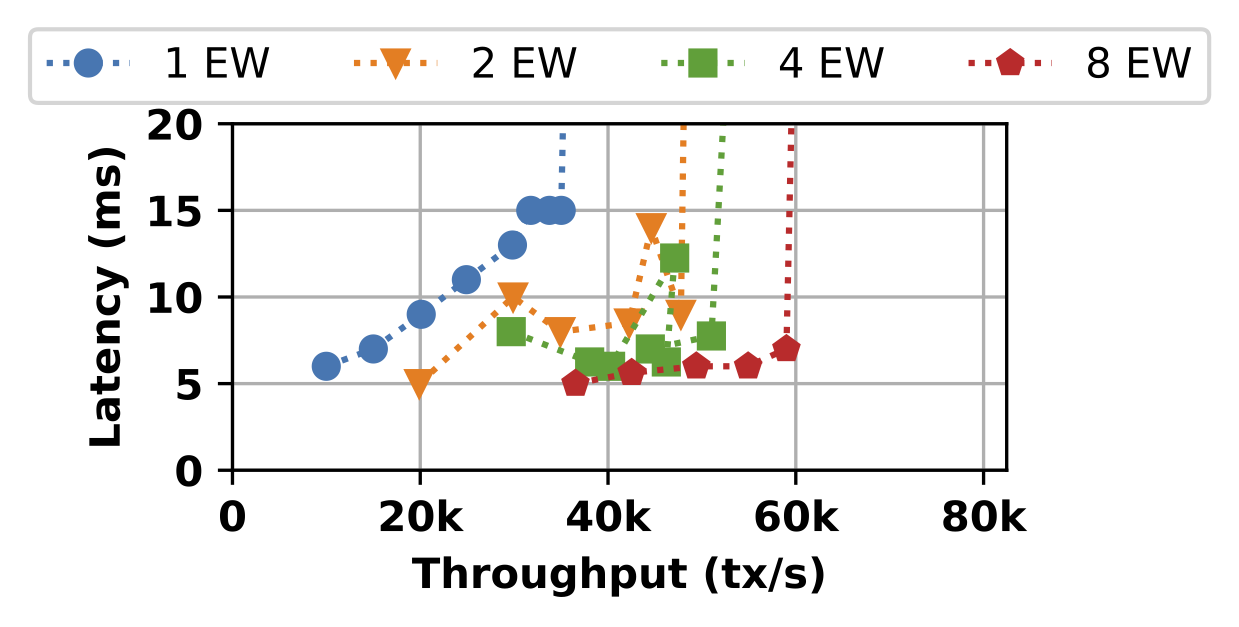
We observe that for any number of execution workers (EW), Pilotfish maintains a low sub-20 millisecond latency envelope. Significantly, we also observe that the per-transaction latency decreases as we add more EWs. At a low 6 to 7 millisecond latency the eight EW configuration processes five to six times more individual transfers than the one EW configuration.
Note that latency exhibits a linear increase as the workload grows for a single ExecutionWorker, primarily because of the effects of transaction queuing. More specifically, a single machine does not have enough cores to fully exploit the parallelism of the workload, so some transactions have to wait to get scheduled. This effect no longer exists for higher numbers of ExecutionWorkers, illustrating that adding more hardware has a beneficial effect on the service time by lowering execution latency.
Pilotfish’s scalability is not perfectly linear in this workload. In particular, the marginal improvement in throughput decreases after two ExecutionWorkers. This is due to the computationally light simple transfer workload and throughput not being compute-bound. Thus, adding more CPU resources no longer improves performance proportionally. The next graph, shown below, illustrates the advantages of increasing the number of ExecutionWorkers when the workload is compute-bound.
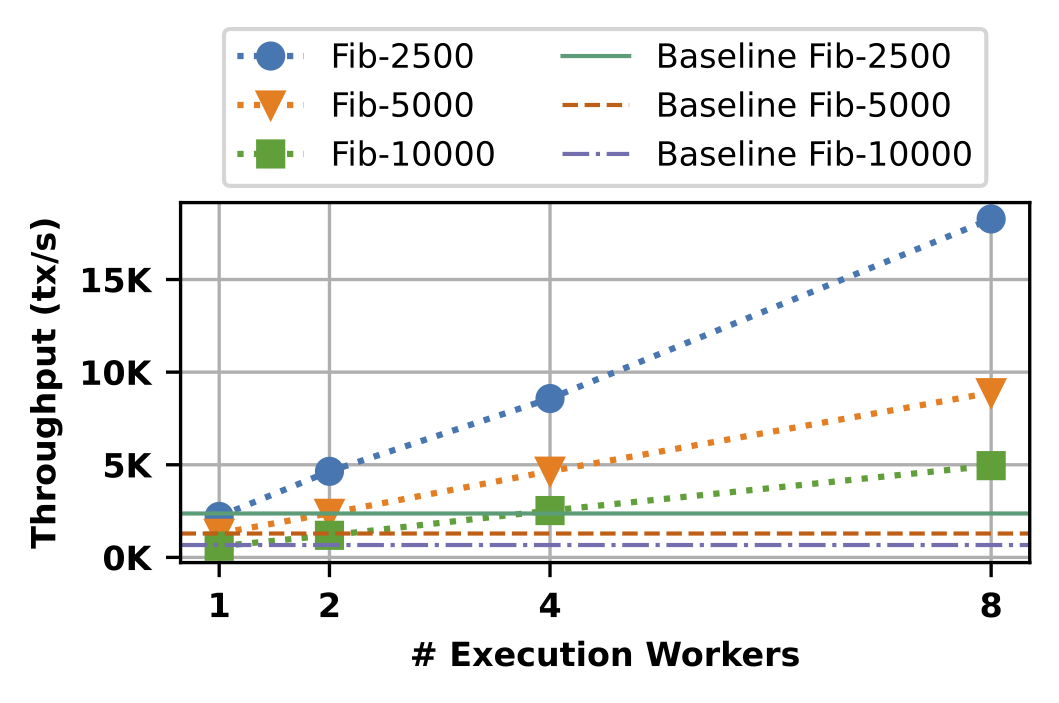
To illustrate the effect of computational intensity, we add some synthetic computation to each transaction. For simplicity, we use iterative Fibonacci computation as our synthetic computation. Ror example, in the graph below, “Fib-2500” means that each transaction computes the 2,500th Fibonacci number. The graph shows how the maximum throughput of Pilotfish scales with the number of EWs for three levels of computational intensity (Fib-2500 is the lowest and Fib-10000 is the highest). As a baseline, we include the performance of the Sui baseline, which runs on a single machine and cannot take advantage of additional hardware.
As the graph shows, in this case, the throughput of Pilotfish scales linearly with the number of EWs available, up to eight times throughput with eight EWs, which is close to ideal.
What’s next?
For now, Pilotfish is a proof-of-concept that shows it is possible to achieve good scale-out execution scalability in lazy blockchains, without compromising latency. In particular, we show that a highly distributed executor leads to low latency execution and higher throughput, even for simple transfers. Furthermore, for compute-intensive smart contracts we demonstrate a near ideal increase in throughput as we add more execution resources.
Pilotfish opens up the way for cheaper computation in smart contracts, free of concerns that the execution of one CPU-bound contract would interfere negatively with other smart contracts.
In the next iteration, we plan to also implement and test support for more than one SW, shard replication and crash-recovery, and support for ultra-fast remote direct memory access networking. We are working on improving our prototype by adding these features and improving its end-to-end performance through engineering optimizations.


